AX: The next evolution in UX
This article was originally published on Agent Experience.
Agents serve as the delegates of end users and are first-class citizens of the digital ecosystem. Their delegated work is an extension of the user’s authority and engagement with a digital service that maintains a mutual exchange of value. Agents then become a medium for engagement with services and the experience that agents have with engaging with a service determines its ability to deliver on end users’ needs. As UX (user experience) focuses on the complete experience users have with a product or service, AX (agent experience) now sits under this discipline of UX study, design, and optimizations needed for UX in the age of AI.
While this article focuses on UX and digital services, incorporation of AX spans further into other consumer journey disciplines such as CX (customer experience), DX (developer experience), etc. and other engagement channels such as voice and phone. e.g. AX will also be a requirement for DX on developer platforms.
It takes a lot to shake up well-established practices, this article explores the concepts that are driving this evolution. This research is meant to be educational and thought-provoking, offering insights into how UX practitioners and others can participate in this area of AI and agentic experiences - even if you’re not building AI within your organization.
What do we mean by agents?
An agent is a user-delegated system (usually backed by LLMs) that autonomously interacts with digital services to complete tasks on behalf of the user while operating within service-defined boundaries. Agents dynamically interpret requests, gather necessary information, execute actions, and return results, enabling users to engage with digital services more efficiently.
Some examples of where agents are used today:
- Developers using agents to generate code, provision resources (databases, SaaS, etc.), analyze code, deploy the code on their infrastructure, etc.
- Support teams using agents to research internal data, forums data, and product specifications to identify ways to solve novel customer issues before grabbing engineering help.
- Home buyers using agents to find different listings that match their needs and inquire about parts that might not meet what they are looking for.
- Parents using agents to set up a perfect evening where one of their available babysitters can watch the kids, a restaurant reservation is made at one of their favorite places at the right time, a Lyft has been scheduled, etc.
There are already countless agents that can be leveraged to take care of the bits of work that humans don’t want to do, can’t do, etc. The end user is delegating this work to a system with varying degrees of “agency” to help them be successful at interacting with a product or service.
Agents are user serving
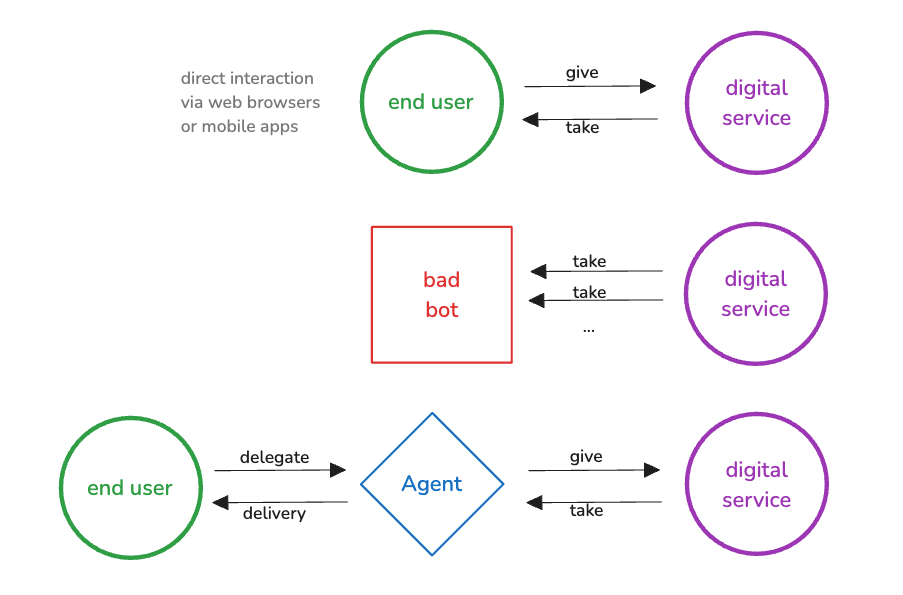
Agents are often miscategorized alongside traditional “bots,” sometimes even as malicious actors. This oversimplification overlooks a critical distinction: agents serve the end users of a digital service. They are not external exploiters but extensions of real users, helping them interact with services as an alternative medium to the users directly using a browser or mobile app.
The rise of AI-driven agents has enabled users to delegate tasks that they previously performed manually. Whether they are developers building with a platform, citizens filing taxes, or customers making purchases, these users remain the same; they are simply engaging through agents instead of direct interactions.
Bots vs. agents
Bots have existed since the early days of computing and now account for nearly 50% of internet traffic. Digital services must decide which bots to support and which to block.
- Permitted bots operate within service guidelines and usually provide complementary value to the digital service or end user, such as search engine crawlers or content preview bots that enhance user experience.
- Malicious bots extract value without benefiting the service or its users—engaging in activities like data scraping, spam, and fraud. These actors operate outside the mutual value exchange.
Agents are a distinct bot system that is neither inherently good nor malicious. Their defining characteristic is that they are dynamic, user-delegated programs with varying levels of “agency”, capable of completing tasks across multiple services. They do this delegated work while maintaining the mutual exchange of value on behalf of the end user - not circumventing it or exploiting it. Once agents complete their task, they deliver the results to the user who authorized the request.
Crawlers for foundation model data
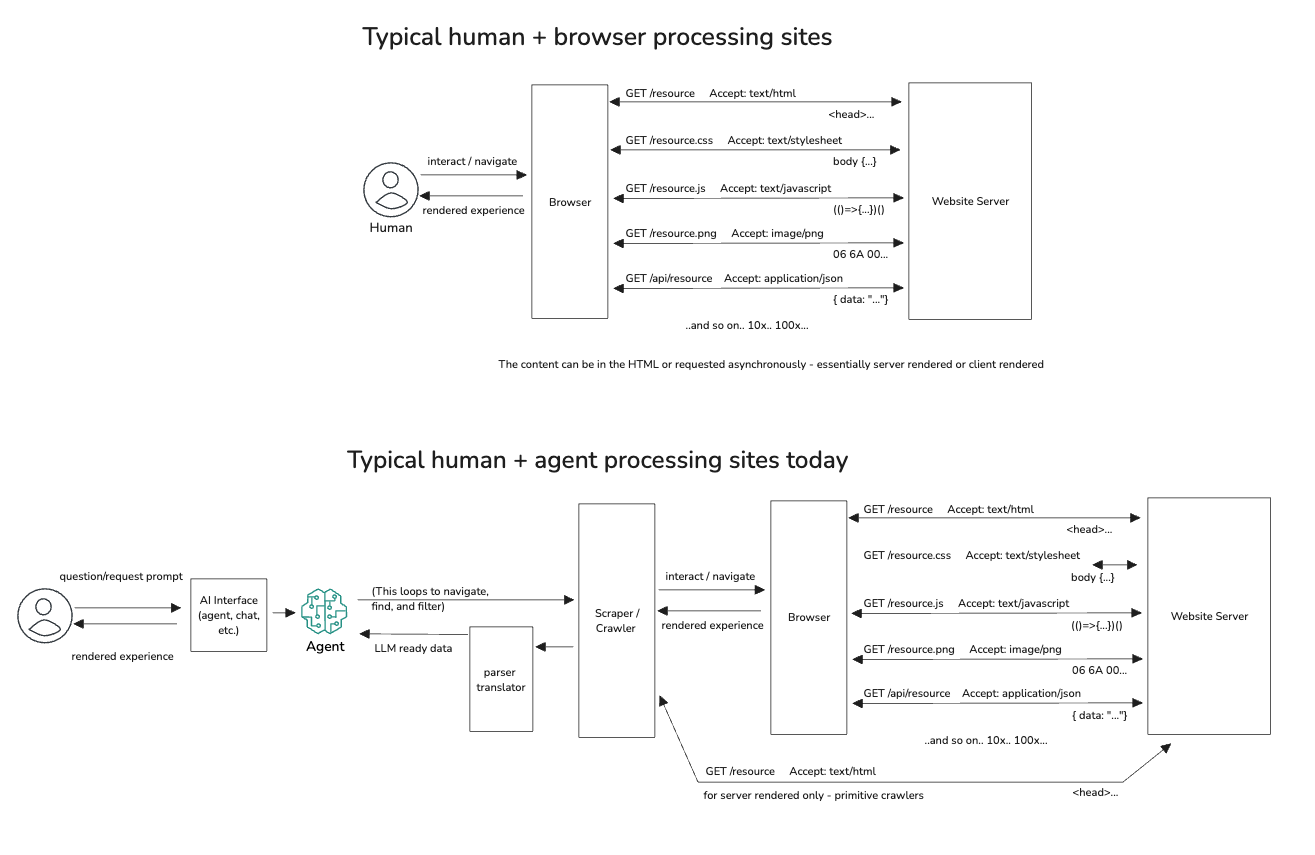
An important distinction should be made around bots that have caused a lot of noise, legal trouble, and issues in the digital ecosystems. Companies like Anthropic, OpenAI, etc. that build foundational models have also used web scraping bots to crawl the internet and pull information from the internet. These are not agents, nor are they delegated by end users, they are traditional bots in every sense. Depending on the company’s practices, these bots land in different camps of valuable for digital services and bad digital citizens to some. Supporting AX is not endorsing the practices of the crawler bots that these companies leverage.
Adoption is shifting behaviors
While there are a lot of opinions on AI, its abilities, impacts, etc. there is no questioning the fact that people are using these tools. In Feb 2025, OpenAI sees 400 million active weekly users, GitHub Copilot has over a million paid subscribers, and so on. The numbers of users, downloads, etc. are measured in the millions with these tools. That is already sufficient to say end users are changing their habits but there’s no questioning the fact that in 1 year, 5 years, 10 years, these will have become embedded into the muscle memory and established as defaults for the generation of customers and organizations coming up.
Poor AX makes unhappy users
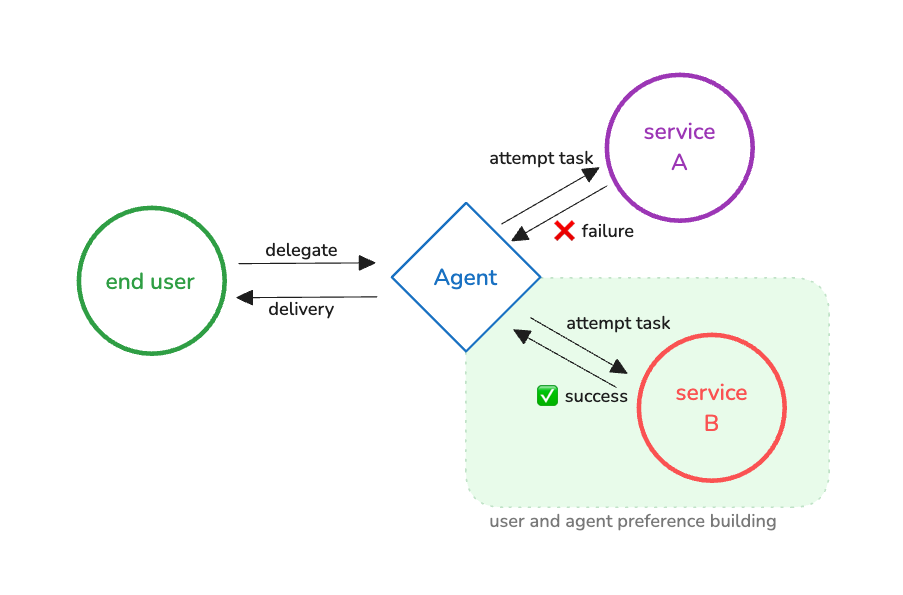
The process of improving AX is the process of determining how easily agents can access, understand, and operate within digital environments to achieve user-defined goals. Therefore, when there is a poor AX (agents don’t have access, unaware of how to user the service, etc.) they are unable to achieve their goals using agents. Even though alternatives may exist, they invested time and energy trying to work through a medium without success. This is friction for the users that prefer agent-based medium of working, are dependent on agents, or otherwise leverage an agent for this task. This friction has resulted in an unhappy user and less total user experience with the digital service.
When this happens, unhappy users run the risk of causing many negative impacts to the digital service:
- Immediate lost customer - they decide not to buy/use and won’t put any more effort into it with a given digital service. Agents, where allowed, will also offer or automatically use alternatives to the service.
- Increased support burden - if the user expects or requires an agent to work with a digital service, they will create tickets, add forum posts, call the support team, etc.
- Decreased preference from users and agents - where users or agents have a choice, they will use the path of least resistance to achieve their goals to the standards they require. Not only is this a potential loss for current opportunity but can instill a long term loss due to preferences.
AX support is a decision about users
Digital services always retain the choice of supporting agents interacting as delegates for end users. There can be various reasons that they decide to do this. On the surface, this consideration feels like a technical one or one related to the agent system itself but it’s not. Regardless of if a digital service decides to actively provide a good AX or completely block agents, the question that’s being asked is not “Should this service support agents?” it is rather “Should this service support users that use agents?”
If the answer is yes - “Yes, these services will support users that use agents.”
If the answer is no - “No, these services will not support users that use agents.”
If the question isn’t or hasn’t been asked - “We have no idea if we support users that use agents.”
Every way you view the question of AX support, it’s always about the users.
Conclusion: The AX evolution in UX
We’ve established that agents are end user delegated systems that maintain mutual exchange of value, the adoption of agents is already extremely high - becoming a default medium for many, poor AX has immediate impacts on end user happiness where agents are used, and the decision to support a good AX is itself a question about which users is the digital service interested in serving. With this, UX is impacted by all major facets of AX support which drives the need for AX to be a top focus around concerns, opportunities, and optimizations needed for UX in the age of AI.
What will this evolution bring?
User centricity is at the core of UX and AX. Evaluation can then start from the same place as with any other medium… by asking what are the user needs and how can we support them via their preferred medium? With that, most of the tools, patterns, techniques, etc. for assessing good UX, testing it, and studying it look the same.
Where things are going to look different and new skillsets will be needed:
- New tools for automated evaluation of AX quality. How do you assess if you’re improving AX in a way that gets you closer to your UX goals and avoids regressing in other areas?
- Giving up control and reinforcing influence. AI systems for which agents are backed rely on non-deterministic systems, can use different models, and provide internal context which can be conflicting. Embrace the mindset of shifting from controlling every detail to the influence of agents with mechanisms for providing context and other capabilities being invented to drive agents.
- There’s no substitute for using the tools that your end users use. Given the digital service you’re evaluating, these tools can vary and their abilities to use any given service will as well.
- Areas that aren’t invented yet such as feedback loops for agents, reliable identifications of models and agent sources, and standards around interaction.
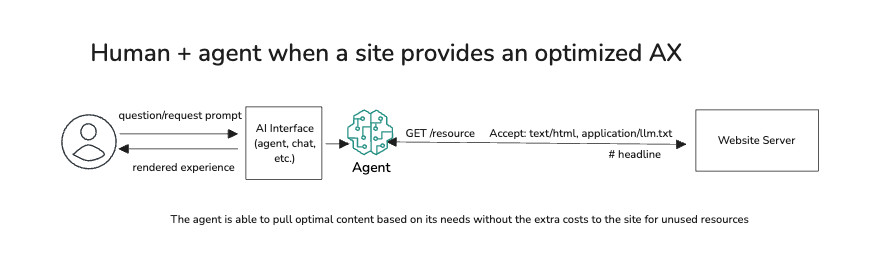
- Context and documentation for agents to effectively navigate and use services is not the same as those that we provide humans. Tools like MCP, LLMs.txt, Arazzo, and others will become standard parts of the stack like we see with human-oriented documentation and support systems today.
As designers, developers, builders, product owners, business leaders, etc. who care about our end users and how they can achieve the best outcomes from our offerings we invest heavily into UX (or DX, CX, or other user persona focused experiences). It’s time to start asking about how our digital services are going to support users using agents to interact with your digital service.
Get involved in the open conversations on agentexperience.ax if you’re interested in contributing to these conversations or helping invent the future of AX + UX.